《图像处理系统》创新性技术2:邻域存储体的理论及其应用
文 | 清华大学电子工程系 苏光大
本文详细的论述了邻域存储体的理论和方法以及该理论正确性的验证,同时指出了邻域存储体在解决内存墙问题的作用,并给出了邻域存储体理论的应用实例。
本文提出了基于邻域存储体的算存算一体立体数据处理技术,实现了高速图像处理。
1 前言
大模型、大算力,是当前科技前沿热点。在大模型训练等方面,英伟达公司的A100、H100芯片显露出超强的能力,但GPU芯片的高功耗、高价位等问题也彰显无疑。
冯诺依曼架构的先进性已经褪色,存算一体、算存算一体、感存算一体计算应运而生。这些新型计算模式彰显出存储体的重要性,而克服内存墙的影响则是新型计算模式的重要方向。
本文提出的邻域存储体具有单个存取周期存取多数据的能力,在理论上消除了内存墙的负面影响。
在邻域存储体基础上,我们实现了算存算一体计算,大幅度提升了算力。
2 通用存储体存在的内存墙问题
冯诺依曼架构在计算模式中占据重要地位,对计算机的发展起着极为重要的作用。如图1所示,冯诺依曼架构包含存储、控制和计算单元。计算机进行运算,需要先把指令数据存入主存储体,再按顺序从主存储体中取出指令一条一条的执行。访问主存储体的速度直接影响计算机的性能。随着处理器性能大幅提升,而内存访问速度却提升较慢,使得处理器的处理速度远远快于内存的存取速度,内存墙问题严重的影响了计算机运行速度。
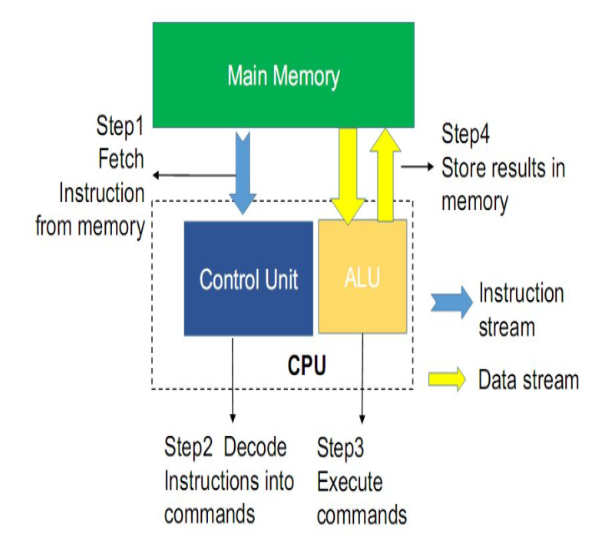
图1 冯诺依曼架构示意图
内存墙问题不仅仅影响了计算机的运行速度,而且广泛的影响到计算技术的众多邻域。处理器与通用存储体之间的数据通道, 存在内存墙。把数据从存储体搬到处理单元,比运算本身还耗时。运算单元增多,存储体供应不上数据。另一方面,经多个运算单元处理得到的多个数据,难以高效的存入存储体,由此形成数据堵塞,导致处理速度变缓。
图2给出了GPU芯片与外部DDR芯片联结的示意图。
 图2 GPU芯片与外部DDR芯片联结的示意图
图2 GPU芯片与外部DDR芯片联结的示意图
图2中,如果GPU芯片访问外部的由DRAM芯片构成的通用存储体,则存在内存墙问题。我们可以看到,英伟达公司采用GDDR5存储芯片并形成高达384bit的存储体字长、超过6000Mhz的显存频率、数千个CUDA核、高端布线工艺,由此实现了高存储体带宽。显然,诸多举措有效的改善了内存墙的影响。
与GPU板的技术路线不同,我们采用邻域存储体来克服内存墙的影响。
3 邻域存储体理论的产生与应用的历史沿革
1983年4月,笔者发表了“物体的边界跟踪与周长面积的确定”论文,论文中采用的算法用到邻域(如3x3)图像处理技术。在算法的执行中,读取存储体的邻域图像数据又慢又繁,一次读操作,只能读出1个数,9次读才能读出3x3邻域图像数据。这一过程,充分说明了内存墙的弊端,笔者也由此萌发了研究邻域存储体的思想。
笔者于1987年发表了“高效率的图象帧存”论文。该论文指出:“在图象硬件处理中,硬件处理的速度和图象存储体的传输效率密切相关,其图象存储体的数据传输率和数据有效性是影响硬件处理速度和决定硬件开销的重要因素。”
该论文“提出了一种图象存储体智能存取的初步构思,主要用以解决用户存取可变、用户存取速率可变、用户存取数据的相邻邻域可变的问题,以期提高存储体的数据有效率。”
该论文前瞻性的提出了存取存储体的邻域数据问题。
该论文前瞻性的提出了存储体数据传输率和数据有效性相结合的存储体有效带宽问题。
笔者于1990年6月承担了清华大学研究基金项目“线跟踪算法及其硬件实现”,我们研发团队进行了二值图象邻域处理机的研制。在硬件设计上,采用了存储芯片堆叠技术。在理论上,探讨了邻域寻址的方法。截止到1992年6月,限于当时芯片水平低下,虽然进行了硬件的系统设计等工作,但没能实现二值图象邻域处理机。
经过3年的持续研究,我们于1997年6月,研制成功了NIPC-1邻域图像并行计算机,高速实现了Roberts和边缘跟踪等算法。
NIPC-1加速板插入微机的ISA总线槽内。
NIPC-1加速板的邻域存储体采用了存储芯片堆叠技术,在一个读或写操作周期内实现了2x2灰度邻域图像数据的并行存取。采用了存储芯片堆叠以及所堆叠的每个存储体芯片的数据bit位分段裂变技术,在一个读或写操作周期内实现了3x3二值图像邻域数据的并行存取。
“实现邻域图象数据并行存取的方法及邻域图象帧存储体”的发明获得国家发明专利,这是一项原创性的发明。
1999年2月我们在电子学报杂志上发表了“邻域图像帧存储体的理论及其实现”论文,论文截图如图3 所示。论文提出了邻域图像帧存储体的理论,实现了邻域图像数据的并行存取,取得了比国内外一些大型图像处理系统更高的图像处理速度。特别是,论文提出“可以说,图像帧存的数据流是影响高速图像处理的瓶颈这个结论已不尽正确”的论断,前瞻性的指出了邻域存储体在推倒内存墙方面的积极作用。
 图3 “邻域图像帧存储体的理论及其实现”论文截图
图3 “邻域图像帧存储体的理论及其实现”论文截图
我们于1999年研制成功了NIPC-2邻域图像并行计算机,NIPC-2加速板采用PCI总线,在一个读或写操作周期内实现了3x3灰度邻域图像数据的并行存取。
NIPC-1、NIPC-2夯实了高速邻域图像处理的基础,我们于2006年9月承担了国家自然科学基金项目“大邻域图像并行处理机”的研究。2008年1月18日,我们研制成功“NIPC-3邻域图像并行计算机”,实现了在邻域存储体一个读操作周期内并行处理24x25个像素点的灰度图像邻域数据。该系统通过了教育部的科技成果鉴定,邻域图像处理速度达到了国际最好水平。
2019年,我们研制成功了嵌入式的NIPC-4算存算一体高速处理板。
2022年,我们研制成功了嵌入式的NIPC-5算存算一体高速处理板。
4 邻域存储体的理论与方法
定义1:邻域存储体 Neighborhood Memory
采用多个存储体芯片堆叠以及所堆叠的每个存储体芯片的数据bit位分段裂变技术组成的存储体,称为邻域存储体。在邻域存储体的一个读或写操作周期中,并行读出邻域存储体的一维邻域多数据、二维邻域多数据或将一维邻域多数据、二维邻域多数据并行写入到邻域存储体中。邻域存储体,简称为N-M(Neighborhood Memory)。
4.1 存储芯片堆叠
4.1.1 存储芯片二维堆叠

左图:4个存储芯片2x2堆叠 右图:9个存储芯片3x3堆叠
图4左图中,a00芯片存储2i行2j列的数据,a01芯片存储2i行2j+1列的数据,a10芯片存储2i+1行2j列的数据,a11芯片存储2i+1行2j+1列的数据。由4个存储芯片构成邻域存储体,可以实现2x2邻域数据的并行存取。
图4右图中,9个存储芯片采用类似于图4左图的结构,组成并行存取3x3邻域数据的邻域存储体。
4.1.2 存储芯片一维堆叠
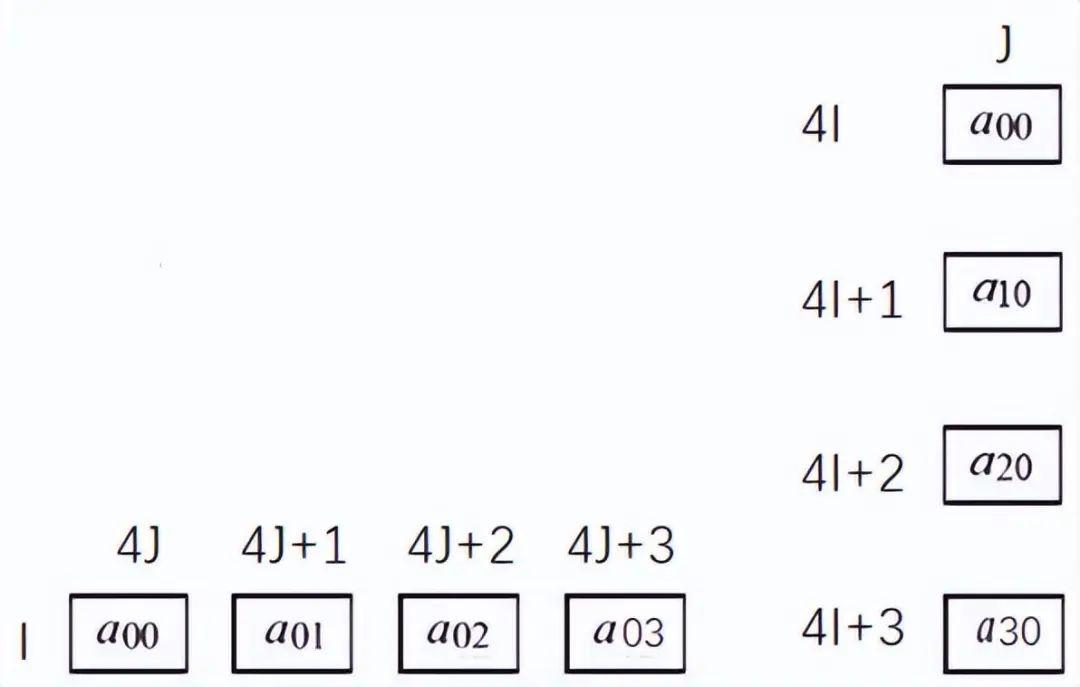
在图5左图中,由水平排列的4个存储芯片组成邻域存储体,实现1x4的邻域数据的并行存取。图5右图中,由垂直排列的4个存储芯片组成邻域存储体,实现4x1的邻域数据的并行存取。
4.2 存储芯片堆叠技术的局限性
存储芯片堆叠以多芯片实现了邻域数据的并行存取,这是以资源堆积实现的,但存在大邻域并行存取的难题。要实现4x4、5x5、6x6的二维邻域数据并行存取,则分别需要16、25、36个存储芯片。如果要形成更大的邻域数据,则需要更多的芯片,电路的设计和实现都很困难。笔者了解到,当前1个处理器所连接的存储体,其最大的存储芯片堆叠数为8片。
这里来探讨采用存储芯片堆叠技术实现大邻域数据并行存取的方法。
以4x4邻域并行存取为例。芯片矩阵A中有a00等16个按照4x4排列的存储芯片,虚线划分为四块,由c00等4个芯片分别替代对应的四个芯片。地址矩阵B给出了c00等4个芯片的对应地址。


关键的问题是如何实现这种芯片替代?
通过研究,我们找到了采用存储芯片的数据bit位分段裂变技术来实现这种存储芯片的替代方法。
4.3 存储芯片数据bit位分段裂变
4.3.1 存储芯片数据bit位二维分段裂变
图6给出了一个存储芯片数据bit位二维裂变的实例。
 图6 32bit字长裂变为4个8bit的邻域数据
图6 32bit字长裂变为4个8bit的邻域数据
图6中,存储芯片的数据bit位为32bit。32bit字长分段裂变为4个8bit,按照图6所示的排列可实现2x2邻域数据的并行存取。
4.3.2 存储芯片数据bit位一维分段裂变
图7给出了一个存储芯片数据bit位一维裂变实例。
 图7 存储芯片数据bit位一维裂变实例
图7 存储芯片数据bit位一维裂变实例
图7中,存储芯片数据bit位为32bit。32bit字长分段裂变为4个8bit,按照图7所示的排列可实现1x4或4x1邻域数据的并行存取。
4.4 存储芯片堆叠加数据bit位分段裂变
图8给出了存储芯片堆叠加数据bit位分段裂变的示意图。
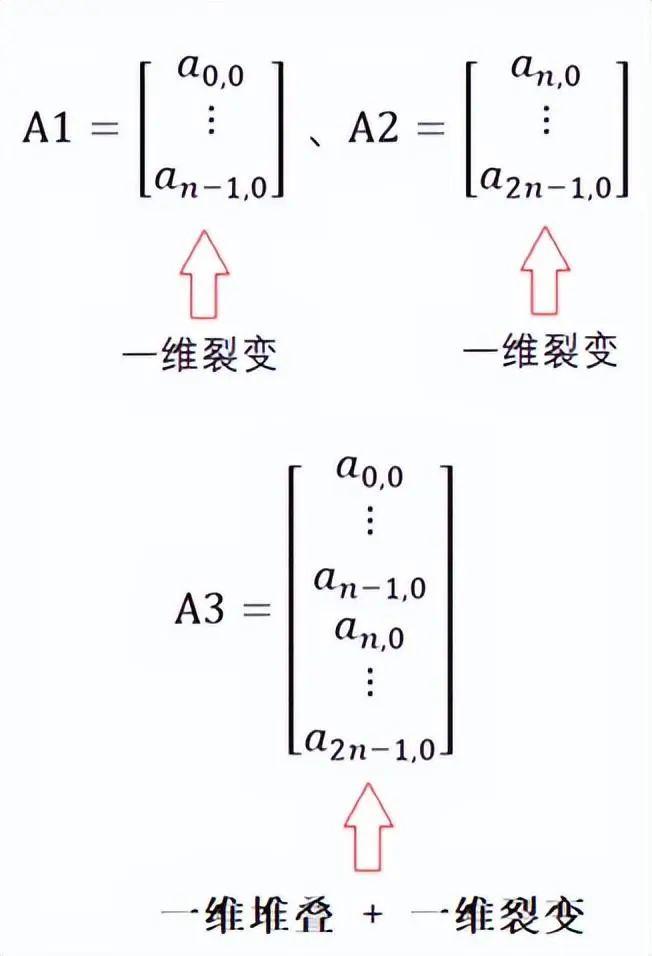 图8 存储芯片堆叠加数据bit位分段裂变的示意图
图8 存储芯片堆叠加数据bit位分段裂变的示意图
图8中存储芯片A1、A2的数据bit位均按一维分段裂变为n段,等效于不同地址的n个数据位。2个存储芯片一维垂直堆叠形成2n段,等效于不同地址的2n个数据位。每个芯片数据bit位均按一维分段裂变为n段,M个相同的存储芯片等效于不同地址的m*n个数据位。也就是说,在存储体的一个读或写周期里,能够读出或写入m*n个数据。如某存储芯片数据位为128bit,8bit为一段,可存储16个8bit的灰度图像数据。8片相同的存储体芯片,可存储128个8bit的灰度图像数据,也就是说在存储体的一个读或写周期里,能够读出或写入128个8bit数据,提高128倍存取效率。可以想象,存储芯片数据位为256bit、512bit、……,所提高的存取效率会达到更高的期待值。现在的处理芯片能承受吗?
5 邻域存储体理论的验证
NIPC-1、NIPC-2加速板验证了存储芯片堆叠技术,NIPC-3加速板则验证了存储芯片堆叠、存储芯片数据bit位分段裂变以及存储芯片堆叠加数据bit位分段裂变技术。
NIPC-3加速板的邻域存储体由4片64bit字长的SRAM存储芯片组成。在一个读周期内读出32个8bit的图像像素,处理器在单处理周期内,可同时处理600点图像数据。图9给出了600点图像数据形成的示意图。
 图9 600点图像数据形成示意图
图9 600点图像数据形成示意图
我们研制成功的NIPC-3邻域图像并行计算机得到了国家自然科学基金支持,于2008年1月8日通过教育部科技成果鉴定。鉴定委员会认为:
NIPC-3邻域图像并行计算机主要创新点在于:
(1)基于不完全轮换矩阵的邻域图像数据形成方法,为并行处理奠定了基础,实现了邻域核可变的数据结构,最大邻域核达到25x24;
(2)通过数据结构在算法、存储、处理中保持一致,建立了先进的并行体系结构,可同时处理600点图像数据,实现了高速图像处理。
NIPC-3邻域图像并行计算机适用广泛,已在人脸识别上取得了初步的应用。
鉴定委员会一致认为,该系统总体水平处于国内同类系统领先,在大邻域图像核和邻域图像处理的速度上优于目前可查到的国际最好水平。
科技日报及时的报道了这项科技成果(图10),在发明专利方面也得到了高度评价(图11)。
 图10 科技日报的报道
图10 科技日报的报道
 图11 发明专利方面的表彰
图11 发明专利方面的表彰
6 邻域存储体理论的应用
邻域存储体理论成功应用于NIPC-5算存算一体的高速图像处理系统。
图12给出了基于邻域存储体的算存算一体立体数据处理(如实现3x3邻域图像处理)的示意图。
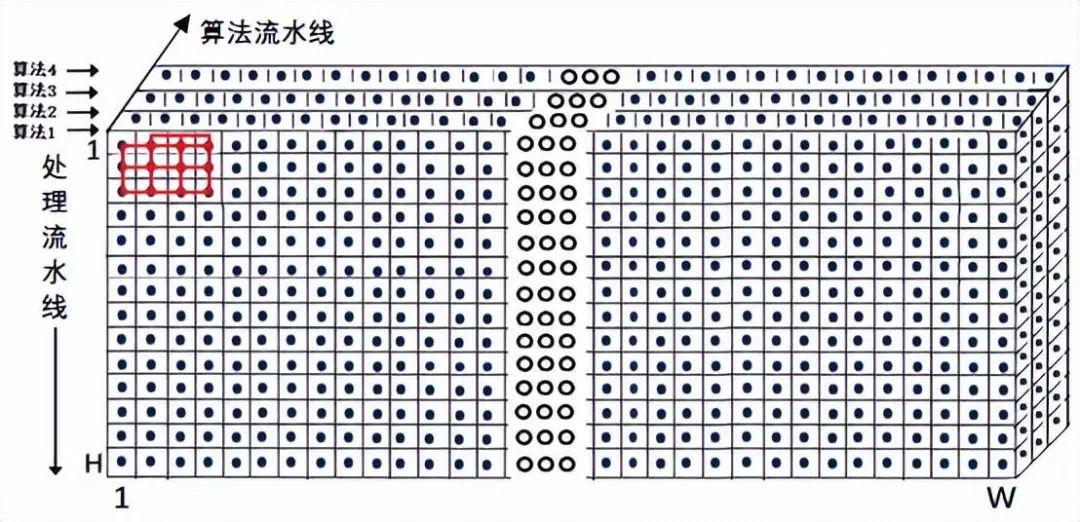 图12 算存算一体的立体数据处理示意图
图12 算存算一体的立体数据处理示意图
如图12所示,在一个存储体页面读周期T0内读出一行W个邻域图像数据,再依次读出下一行图像数据。在读出每行数据的同时,采用算法流水线和处理流水线并行处理技术,逐行顺序完成1、2、3、4种算法立体数据的高速处理,处理时间M=H*T0。
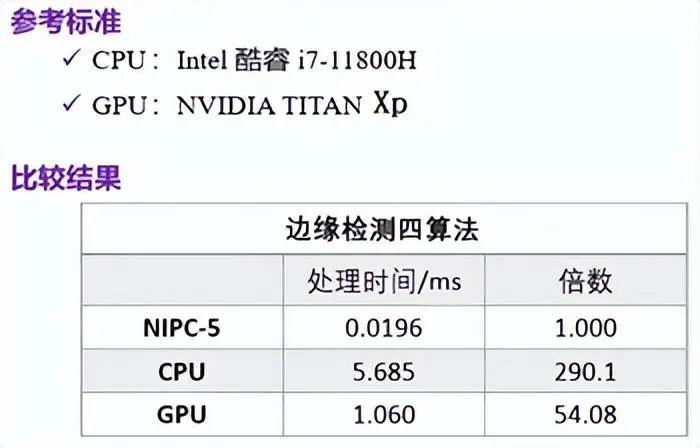
在NIPC-5算存算一体的高速处理板上对512x512x8bit的图像进行高斯滤波+sobel滤波+中值滤波+二值化的4个算法流水线处理,耗时仅为0.0196ms,每个算法平均耗时小于5µs。
分别对比CPU、GPU执行相同算法的处理速度,比较结果如下:
7 结束语
图12给出的算存算一体的立体数据处理方法,处理一幅512x512的灰度图像,4个算法仅仅耗时0.0196ms。这个指标,仅仅使用了普通的器件(如DDR4)、较低的存储体存取频率(如250Mhz)、普通的布线工艺。该指标预示着算存算一体的高速处理板具有实时处理上百路视频图像的能力,也预示着具有高速实现YOLO算法的能力。
笔者在清华大学电子工程系曾建立了图像识别与高速图像处理实验室,希望实现软硬件技术的协同发展。
在图像识别方面,我们主要研究人脸识别综合技术,应用于2008年北京奥运会、户籍查重和视频图像侦查,协助公安部门破获了大量刑事案件。
在高速图像处理方面,从1983年开始,从一个想法到具体实现;从二值图象邻域处理机到NIPC-5算存算一体的高速图像处理系统,经历了漫长的40年。
我们希望,走一条人工智能软件与人工智能硬件相结合的科研路。在NIPC-5算存算一体的高速图像处理系统上,目前我们正在做多目标检测、识别、跟踪算法,希望有新的突破。同时,我们也期待下一个版本(NIPC-6),在低功耗的指标下,实现更高的处理速度。
参考文献
[1] 苏光大.《图像处理系统》[M].北京:清华大学出版社.2020.
[2] 陈实、苏光大、陆建华. 可配置高速二维卷积处理器设计与Gabor滤波应用. 清华大学学报(自然科学版)2010年第50卷 第4期 p581-585
[3] 一种大邻域图像并行处理方法.发明专利.授权公告日:2010年4月21日.发明人:苏光大,陈博亚
[4] 实现邻域图像并行存取的方法及邻域图像帧存储体.发明专利. 授权公告日:2002年3月20日.发明人:苏光大,左永荣
[5] Guangda Su; jiongxin Liu; Yan Shang; Boya Chen; Shi Chen.Theory and application of image neighborhood parallel processing. IEEE 16th International Conference on Image Processing (ICIP2009), Cairo, Egypt,p2313-2316
[6] 苏光大.邻域图象处理机中新型的功能流水线结构.电子学报.2000年Vol.28 No.8: p120-123
[7] 苏光大,左永荣.邻域图象帧存储体的理论及其实现.电子学报.1999年V0l.27 No.2p83~86
[8] 苏光大,丁晓青.高效率的图象帧存.全国第六届模式识别与机器智能学术会议论文集 1987年10月 iv-41~44
- END -
(文章转载自慧聪物联资讯 ,,以上图文版权均归原作者所有。如涉侵权等事宜,请联系我方予以删除。)
- END -
(文章转载自慧聪物联资讯 ,,以上图文版权均归原作者所有。如涉侵权等事宜,请联系我方予以删除。)