OpenAI给科技行业敲响警钟,中国必须要有自主“大模型”
腾讯科技
发表于

来源丨腾讯科技
采访、编辑丨郭晓静
● 生成式AI技术,是否会带来一场堪比移动互联网的新商业浪潮?
● 这是否会给目前的商业格局带来巨大的改变?
● 生成式AI赛道,到底有哪些商业模式可以挖掘?
● 中国的头部科技企业,抓住这场新的AI浪潮了吗?
● 高端芯片被限,中国还有可能发展自己的AI大模型吗?
01
 全球首例AIGC技术辅助商业化动画片《犬与少年》,动画场景由AI绘制
全球首例AIGC技术辅助商业化动画片《犬与少年》,动画场景由AI绘制
02
现在的生成式AI,

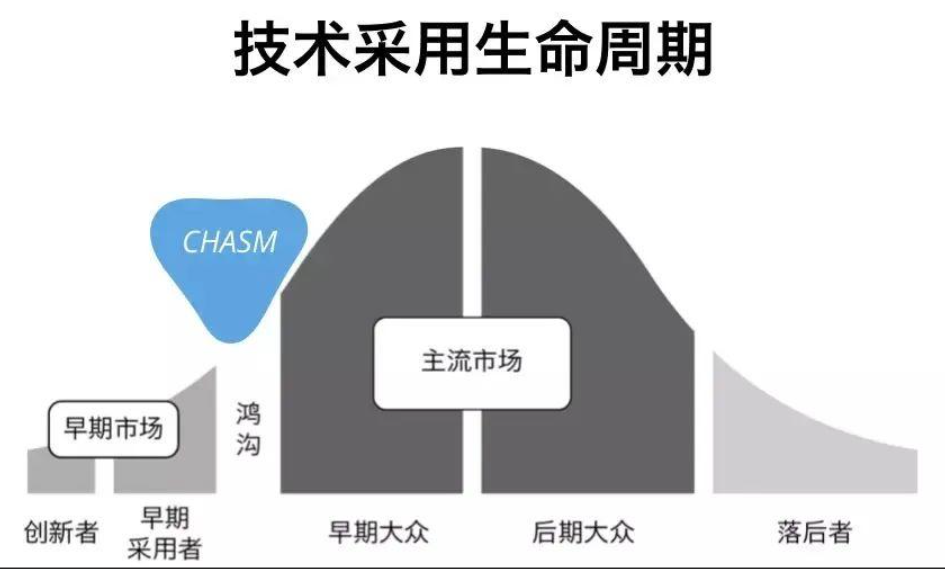
03
有些专家纠结ChatGPT“是否有技术突破”其实暴露了无知

04
高端芯片被限制,
(文章转载自腾讯科技,以上图文版权均归原作者所有。如涉侵权等事宜,请联系我方予以删除。)