告别捅嗓子?AI手机程序通过声音检测新冠,准确率已达到89%

大数据文摘出品
不知道大家对做核酸怎么看,反正文摘菌的喉咙已经起茧了。
不过为了防疫大局,也为了知道确定自己的健康状况,通过核酸确认自己没有感染新冠又在所难免。
等等……有没有其他方法可以检测自己有没有中招?
最好还是不用出门的那种。
你别说,这样的技术还真有可能出现。
9月8日在西班牙巴塞罗那举行的欧洲呼吸学会国际大会(European Respiratory Society International Congress)上发表的一项研究表明,一款手机应用程序借助人工智能,可以通过你的声音判断中是否感染了新冠肺炎。
目前,这一模型的准确率已经达到89%。
这是不是意味着,将来在家上传自己的声音,就可以代替做核酸了?想想都觉得美妙……

通过声音分辨你是否是阳性,效果优于快速抗原检测
新冠肺炎会影响上呼吸道和声带,导致人的声音发生变化。
在这基础上,马斯特里赫特大学数据科学研究所(Institute of Data Science)的Wafaa Aljbawi女士和她的上司,马斯特里赫特大学医学中心的肺病专家Sami Simon 博士,以及同样来自数据科学研究所的Visara Urovi博士,决定研究是否有可能使用人工智能来分析声音以检测新冠阳性。
他们使用了剑桥大学的COVID-19声音应用程序的数据,该应用程序包含4352名健康和非健康参与者的893个音频样本,其中308人的新冠检测呈阳性。
该应用程序安装在用户的手机上,参与者报告一些人口统计、病史和吸烟状况等基本信息,然后被要求记录一些呼吸声音,包括咳嗽三次,用嘴深呼吸三到五次,在屏幕上读短句子三次。
研究人员使用了一种名为“梅尔谱图分析(Mel-spectrogram)”的语音分析技术,该技术可以识别不同的语音特征,如响度、频率和随时间的变化。
“通过这种方式,我们可以分解参与者声音的许多属性,”Aljbawi女士说。“为了区分新冠病毒阳性患者和阴性正常人群的声音,我们建立了不同的人工智能模型,并评估哪一种模型最适合分类这些病例。”
他们发现LSTM模型优于其他模型。LSTM基于神经网络,它模拟人脑的运作方式,并识别数据中的潜在关系。它擅长时序分析,这使得它适合对随着时间的推移收集的信号进行建模,比如声音。
最终,这个模型的总体准确率为89% ,正确检出阳性病例(真阳性)的能力为89% ,正确识别阴性病例(真阴性)的能力为83% 。
“这些结果显示,与横向流动试验等最先进的检测方法相比,诊断新冠病毒疾病的准确性有了显著提高,”Aljbawi表示,“侧流检测法(快速抗原检测)的准确率仅为56%,但特异性更高,达99.5%。这一点很重要,因为它意味着快速抗原检测将感染者错误地分类为阴性的情况比我们的测试更为常见。换句话说,使用AI LSTM模型,我们可能会漏掉11/100的病例,这些病例会继续传播感染,而快速抗原检测将会漏掉44/100的病例。”
该做核酸还是得做核酸
之所以跟快速抗原检测相比,是因为许多国家目前已经不再进行免费的核酸病毒检测——也就是国内进行的大规模核酸检测。
核酸病毒检测是对采集的病毒核酸进行直接检测,具有特异性强、灵敏度高的特点,是新型冠状病毒检测的主要方法。
快速抗原检测相对来说要简单一些,可以自己完成,主要通过通过检测病毒的抗原来进行分辨,可以作为新型冠状病毒诊断的主要依据之一,但是准确率相对来说低一些。
许多国家目前都以发放快速抗原自测包为主,抗原检测呈阳性的才会要求做进一步检测。
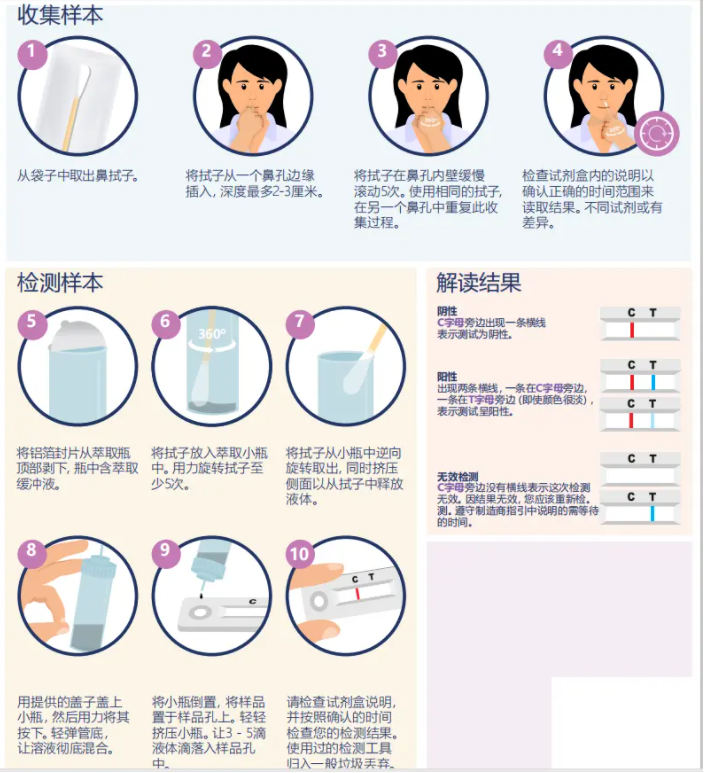
当然,因为这种自测包相对来说操作难度还是有的,所以准确率不太高,因此如果能够通过声音来判断是阳性,那既可以节省资源,又能够获得相对准确的结果,确实是一件好事。
所以说,尽管在假阳性方面,AI表现比较差,会有17%的人被误诊为阳性,但是可以把它作为初筛手段,让声音检测呈阳性的,再去进行下一步检测。
并且,这项技术针对的更多是核酸检测昂贵和/或难以分发的低收入国家。
至于我们,该做核酸还是得做核酸……
外,研究人员说,他们的结果还需要大量的数据来验证,自该项目开始以来,从36116名参与者收集了53449个音频样本,可用于改进和验证模型的准确性。他们还正在进行进一步分析,以了解语音中的哪些参数正在影响人工智能模型。
相关报道:
(文章转载自大数据文摘,以上图文版权均归原作者所有。如涉侵权等事宜,请联系我方予以删除。)