画质增强背后的超分辨率重建技术
本文转载自新机器视觉,来源于数字人才实训基地。文章仅用于学术分享。
前言
从“标清”变“4K”。最近,老视频修复又引起了一波“回忆杀”,许多的老影像、老动画、MV、甚至还有表情包画质都得到了增强,那么画质清晰度提升的背后究竟有着什么样的神奇之处呢?
答案是“超分辨率重建”

正文


分辨率(Image Resolution)很好理解,就是指图片上像素的数量,同等条件下,分辨率越高,图像就越清晰。超分辨率重建中的“超(Super)”就是指把图像的画质从低变高从而带来超额的视觉体验的这种目的,而“重建”则传递了一个十分关键的信息,这些网络上所谓的“高清重制版”并不是所谓的“还原修复”,而是依据残存信息,推测出的画面,通俗来讲就是“无中生有”。
这里我们要正视一个问题,图像的信息,丢失了则视为失去,且不可逆。我们不妨举例来说明一下,小奇拍摄了一张“高清”大图,然后用JPEG格式存储在电脑上,然后把该照片发给了同学A,同学A缩小了一下尺寸,然后发给了同学B,之后的一段时间里,这张图片在各位同学之间被任意传输,最后则变成了一张“失真”小图。那么问题来了,面对这张“失真”小图是否能够顺藤摸瓜找回最初的高清大图?显然不能,这里有两个明显的问题,首先是根本不知道丢失了哪些信息,其次也不知道这些信息是如何丢失的,这种情况就被称为“盲”。换句话说,既然图像损失的过程无法追溯,就不可能精准的倒回原位,那么回到之前的问题,“重建”画面是如何做到的呢?
答案是:深度学习
即将大量数据交给机器,由它们自行探索解决的方法,就好比此时你手里有一张已经受损的图像,你想要将它修复,就要通过未损失的部分不断的进行学习,此后不管遇到什么样的图像都可以将它还原出来。
但是深度学习也有不足,只能做“见过”的东西,比如之前见过的都是“泛黄”老照片,现在突然来了一张被修补的,那么它依旧会按照之前的“泛黄”去处理,因为它无法追溯这种现象的过程。
本质上看,机器学习就是对过往经验的归纳总结,从而解决一些复杂的问题,但是不足之处在于一旦脱离了曾经见过的数据类型,效果就会变得不理想。这种现象被称为“domain gap”即因训练数据和测试数据类型不同而导致效果变差的情况,一般被认为是数据之间存在domain gap。

因此,想要基于深度学习的超分辨率重建在现实生活中有着更加“精确”的表现,就要缩小这种差异,搭建足够逼近真实的数据模型。这里提到的数据并不是网络上随处可见的数据,机器学习常见的训练方式有三类:监督学习、半监督学习、无监督学习,其中监督学习就好比我们在刷题时会看参考答案,通过分析答案和题目之间的关系找到解题思路;而无监督学习就好比在习题集里面找到各类型的题目,将他们按照所考察的知识点进行分类。回到图像修复问题,监督学习一般会得到更好的效果,因此,所谓的“数据”就并不是简单的海量图片,而是一个个像“题目”和“答案”一样是已经匹配好的“数据对”。
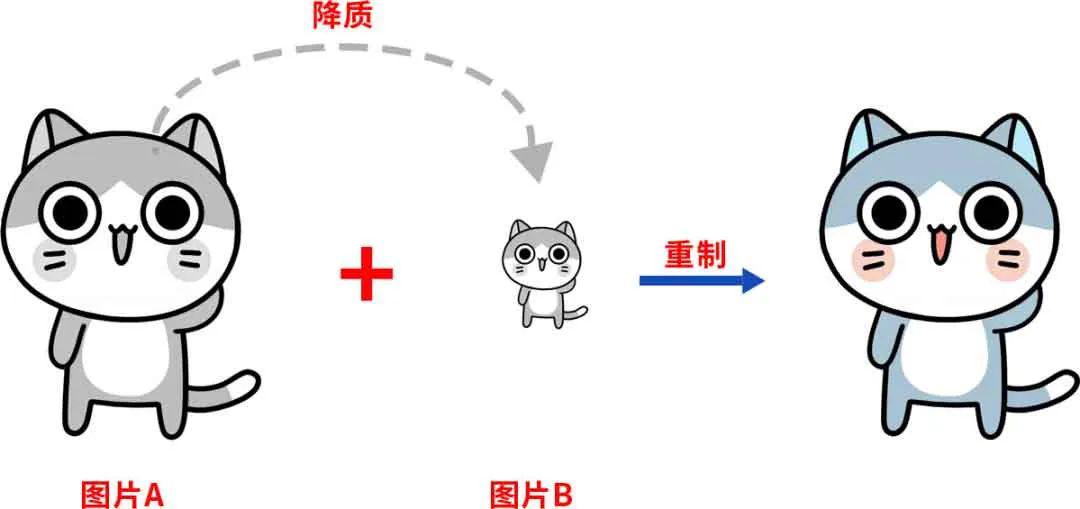
例子
举例来看,上图一张清晰的图像A,和一张经过降质的图像B,它们组合在一起才是一对有意义的数据。反之,网络上的任意一张失真图,如果无法找到与之对应的清晰版,就是无效的。
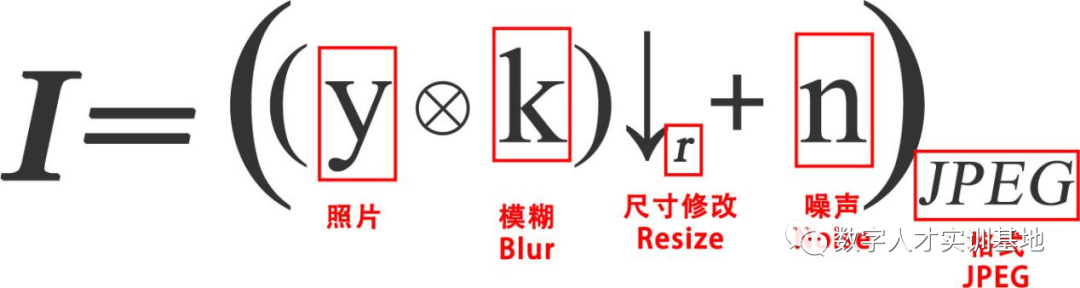
因此,搭建有效的极其逼近真实的数据模型就是深度学习关键的第一步,那么可以尝试写出一个具体的降质模型,比如小奇在拍摄照片的一瞬间由于手抖产生了一些模糊,记作与模糊核K发生卷积,接下来同学A把它缩小了,分辨率下降损失了一部分像素,之后在反复的压缩传输中又积累了很多噪声n,然而,JPEG本身就是一种有损压缩格式,这样就搭建了一个基础模型,当然真实情况要远远比这个复杂的多。模型中每一个参数的值都是未知的,且变化空间极大,互相掺杂在一起,还会出现反复发生、随机组合等情况排列出无数种可能。
另外,这个简单模型并没有考虑到毛边、绿线、划痕、斑点等更复杂的情况。为了更贴近现实,专家们还会进行多次降质,给失真图层层叠加噪点、模糊等,也会对原始图片进行锐化处理以得到更加的感知效果。
如何获得低分辨率图像
要训练一个超分辨率重建模型就需要有“高清”和“低清”的样本对,那么研究超分模型的学者就把获得低分辨率图像的这个过程叫做降级(Degradation)。降级可以用这个公式表示:Ix = D(Iy ; δ)
其中Iy表示高清图像,Ix表示降级之后得到的低清图像,D表示降级映射,δ为模型中的参数。
将这个公式代入到超分模型当中:
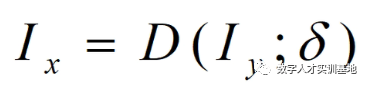
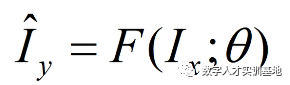
就可以得到下面这个公式:

从以上的过程我们可以看出,超分就是降级的反过程当超分图像∧Iy越来越接近高清图像Iy时,超分模型就会越来越接近降级模型的反函数。所以说,如果降级模型的假设越贴近真实的场景,所以获得的超分模型的效果就会越好。但是在实际的问题中,降级过程是非常复杂的,它会受到图像压缩失真、传感器噪声、噪点、散焦等影响。
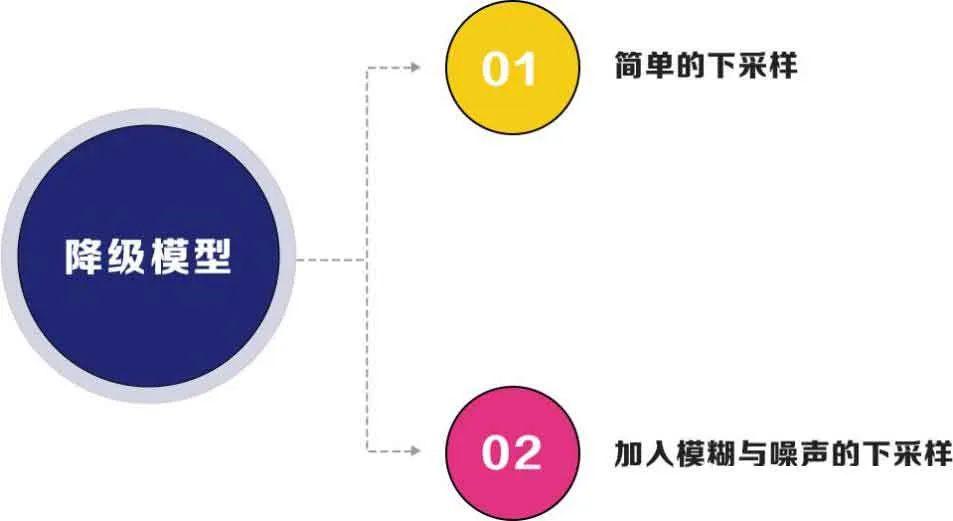
那么现有的降级模型有两种,第一是简单的下采样;另一种是加入模糊与噪声的下采样。
简单的下采样Ix = (Iy)↓s,公式中的↓表示下采样操作,s表示下采样的倍数。就是直接将一个高清图像Iy进行下采样操作得到低清图像Ix,没有多余的其它操作。
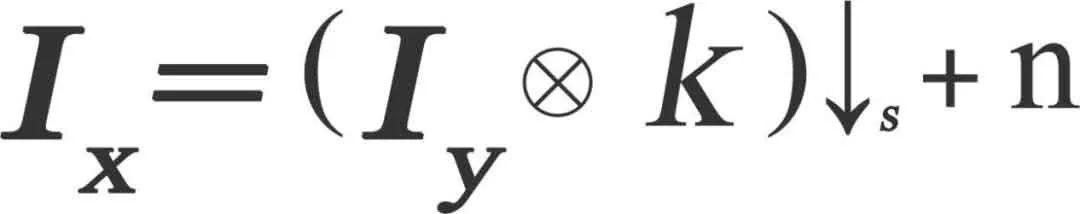
公式中⊗表示卷积,k为卷积核,n为噪声。
那么相应的加入模糊与噪声的下采样,它是将高清图像Iy先进行一个卷积操作,然后再做下采样再加入噪声,最终得到Ix这样一个低清图像。这样的过程就是用加入了模糊和噪声的方法得到的下采样图像和原始的高清图像放入超分模型中。
较为传统的超分辨率重建技术主要包括:基于插值的技术、基于重建的方法、基于非深度学习的方法。
基于插值的技术
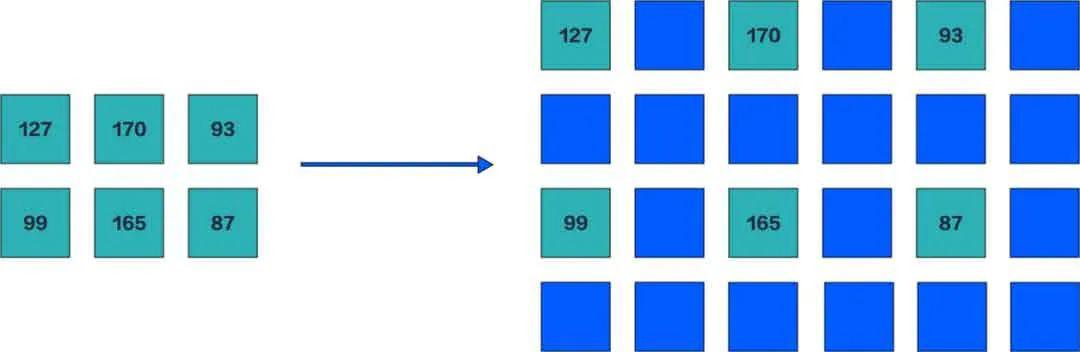
首先基于插值的技术,其实就是在图像中插入一些像素点,这些像素点的值根据临近的像素点来计算出来。那么计算它们的方法一般包括最临近元法、双线性内插法、三次内插法的一些插值方法。
基于重建的方法
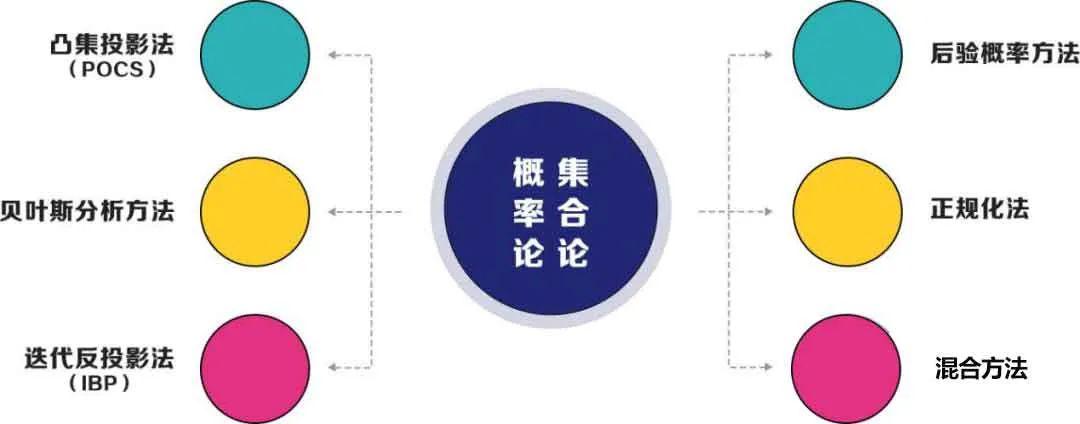
基于重建的方法它的理论基础就是一些数学的概率论或集合论,一般有以上几个超分辨率重建图像的方法,其中混合方法就是将前面几个方法混合在一起。
基于非深度学习的方法
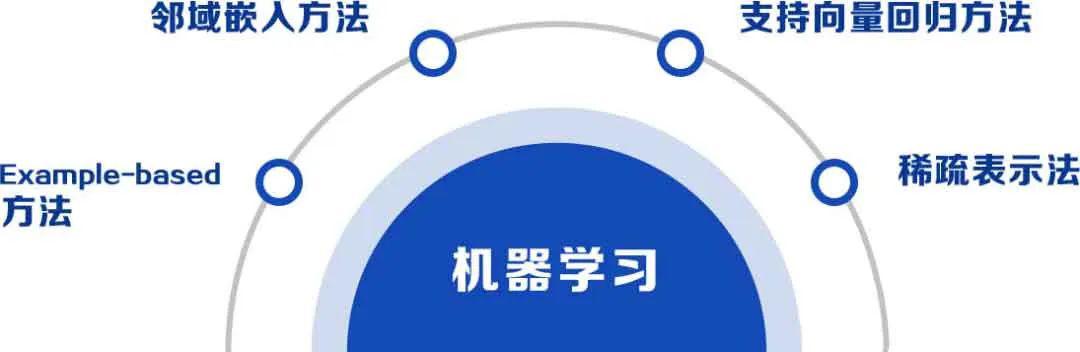
基于学习的方法其实就是基于机器学习的非深度学习的方法,主要包括以上几种方法,以上主要是列举了传统的图像超分辨率重建的一些方法。
基于深度学习图像超分辨率重建问题
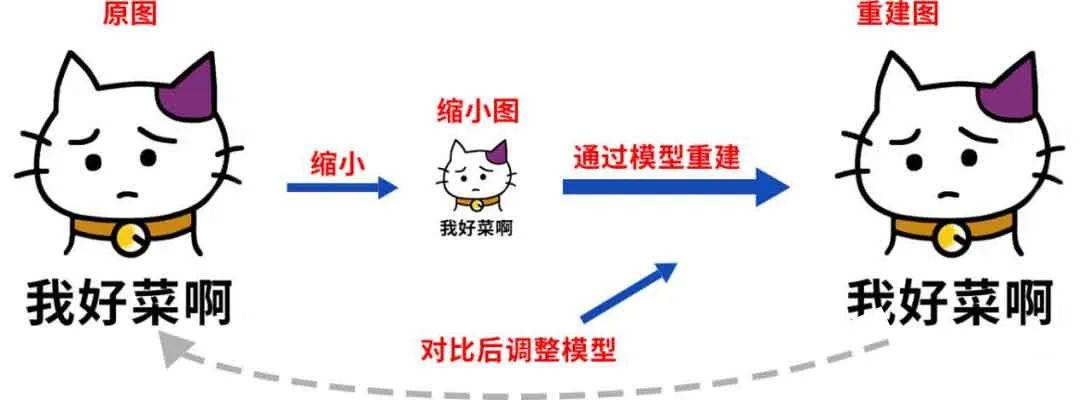
这个问题本身可以把它看作一个监督学习的问题,上图是它的实现过程,首先找到一张原图,将它缩小,得到一张缩小图,然后通过模型重建得到一张重建图,将重建图和原图进行对比,对比后通过调整图形得到模型组合好。得到的重建图足够清晰。
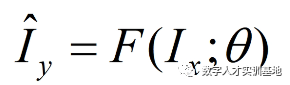
监督学习可以用这样的一个公式将它进行一个符号化,其中Ix和∧Iy分别表示低清图像与超分图像,F表示超分模型,θ为模型中的参数。
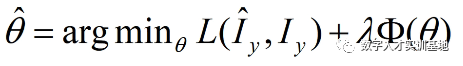
模型的学习目标可以用以上的公式表示,其中L为损失函数,ф(θ)为正则项,λ为惩罚系数。它的目标就是要找到参数θ使损失函数L最小。
然而,这仅仅是针对一张静态的图像,如果想要修复视频,面临的问题将会更多,那么如此复杂的工程,超分辨率重建到底可以做什么呢?实际上,图像处理关乎很多现实问题,比如医院的检查报告、遥感卫星成像、监控图像复原等等。而现在,随着计算机的发展,也为面对这些挑战带来了更多的可能性。
在特定领域的应用
1、深度图超分辨率
深度图记录了场景中视点和目标之间的距离,深度信息在姿态估计、语义分割等许多任务中发挥着重要作用。然而,由于生产力和成本方面的限制,由深度传感器生成的深度图通常分辨率较低,并饱受噪声、量化、缺失值等方面的降级影响。为了提高深度图的空间分辨率,研究人员引入了超分辨率。
2、人脸图像超分辨率
人脸图像超分辨率(又名face hallucination,FH)通常有助于完成其它与人脸相关的任务。与一般图像相比,人脸图像拥有更多与人脸相关的结构化信息,因此将人脸先验知识整合到FH中是一种非常流行且颇有前景的方法。
3、超光谱图像超分辨率
与全色图像(panchromatic image,PAN)相比,超光谱图像(HSI)包含数百个波段的高光谱图像,能够提供丰富的光谱特征,帮助完成许多视觉任务。然而,由于硬件限制,不仅是搜集高质量HSI比搜集PAN难度更大,搜集到的HSI分辨率也要更低。因此,该领域引入了超分辨率,研究人员往往将HR PAN与LR HSI相结合来预测HR HSI。
4、视频超分辨率
在视频超分辨率中,多个帧可以提供更多的场景信息,该领域不仅有帧内空间依赖,还有帧间时间依赖(如运动、亮度和颜色变化)。因此,现有研究主要关注更好地利用时空依赖,包括明确的运动补偿(如光流算法、基于学习的方法)和循环方法等。