传感融合新突破:自动驾驶汽车摄像头失效也不慌
近年来,科学家们一直致力于开发强泛化性系统,希望能将其用于物体检测、导航功能,以及眼下大热的自动驾驶汽车赛道。
对于自动驾驶汽车来说,传感器融合已成为自动驾驶领域不可逆转的技术趋势,但从整体上来看,用于训练机器学习模型的数据集大多为图像数据集,鲜有基于雷达传感器收集的数据集。
不过,这一现状或许很快就会迎来转机——随着异构传感器在感知方面的互补优势,基于传感器融合和深度神经网络来实现对象感知/跟踪方面的研究已经取得了长足进展。
据新智驾了解,美国亚利桑那大学的研究人员已经开发出一种新方法,可以自动生成有标签的雷达数据以及摄像头图像数据的数据集。而且,即使在光学传感器偶尔失效的情况下也能在帧中标记雷达数据。
 图注:论文截图,这项研究已获得索尼研究奖计划的认可。
图注:论文截图,这项研究已获得索尼研究奖计划的认可。
Sengupta表示,他们利用具有噪声的基于密度的聚类方法(Density-Based Spatial Clustering of Applications with Noise,DBSCAN)检测和消除噪声/ 杂散雷达回波,再将雷达回波分离成簇以区分不同的物体。
最后,用帧内和帧间匈牙利算法关联。帧内匈牙利算法将 YOLO 预测与给定帧内的协同标定雷达簇相关联,而帧间HA在连续帧中关联与同一目标相关的雷达簇,以便即使在光学传感器偶尔失效的情况下也能在帧中标记雷达数据。
研究人员首先对雷达及摄像头进行联合校准,通过摄像头图像流上(YOLO)的高精度目标检测算法和关联技术(匈牙利算法,Hungarian algorithm)来标记雷达点云,生成标记的雷达图像和唯雷达数据集。
YOLO 是“You Only Look Once”的简称,虽然它不是最精确的算法,但作为精确度和速度间的折中之选,也有着相当出色的效果。
YOLOv3 就是在YOLOv1 和YOLOv2 的基础上形成的。它不但拥有YOLO 家族的速度优势,检测精度也大幅提升,对于小物体的检测能力更是“傲视群雄”。
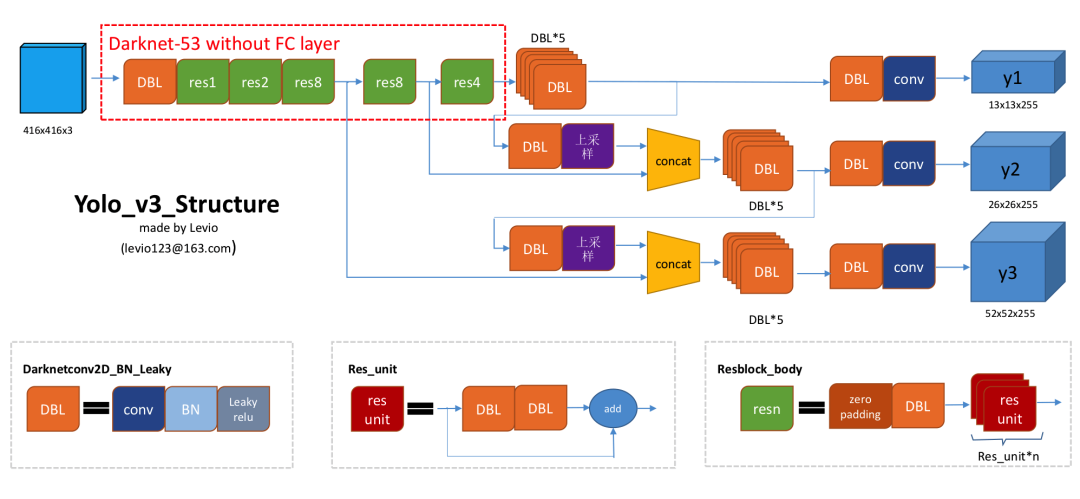 图注:YOLOv3的结构图
图注:YOLOv3的结构图
YOLOv3 算法在图像上只需一个单独神经网络,便可将图像划分多个区域,并预测边界框。
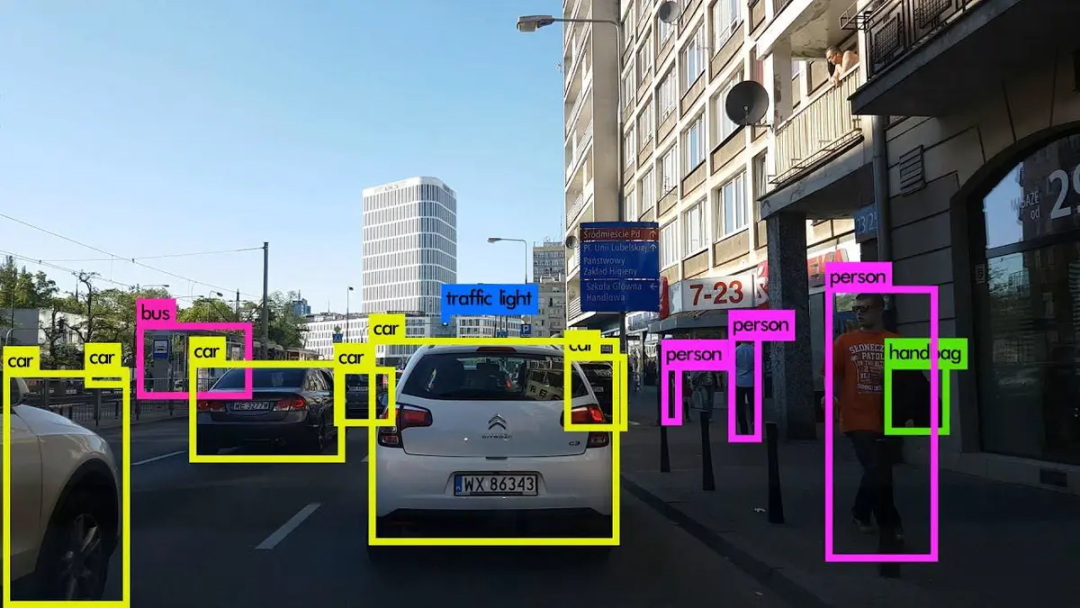 图注:YOLOv3目标检测
图注:YOLOv3目标检测
作为行业共识,基于雷达传感器的深度学习应用需要大量标记训练数据。而标记雷达数据是既费力又费时的密集型劳动过程,通常需要昂贵的人力成本才能将其与获取的图像数据流进行比对。
因此,论文作者Arindam Sengupta 博士提出,“如果相机和雷达同时间查看一个物体,我们是不是可以利用基于图像的物体检测框架(YOLO)自动地标记雷达数据,而不需要手动逐一查看图像。”
这个方法有三大理论背景:
1. 雷达信号处理链 ( Radar Signal Processing Chain)
激光雷达信号链是从原始 3-D 雷达数据立方体开始。
首先,沿雷达的快时间轴执行快速傅里叶变换(fast Fourier transform),其中拍频与发收信号间的时间延迟成正比,这能帮助在 (ρ)范围确定目标距离 (s)。沿慢时间轴的快速傅里叶变换可以用于确定多普勒频率,用于计算目标的径向速度 (v)。
移动目标指示器(Moving Target Indicator)通过延迟线将所需目标与静态杂波隔离开。为了做到更可靠地检测,恒定误报率(Constant False Alarm Rate)会测算目标周围的本底噪声,并通过设置检测信噪比(Signal-to-Noise Ratio, SNR)阈值避检测失误。
最后,沿通道维度的快速傅里叶检测可些帮助确定目标的方位角 (θ) 和仰角 (φ)。从而得到雷达信号处理链的输出结果为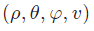 ,然后将球坐标转换为
,然后将球坐标转换为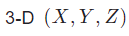 笛卡尔雷达点云 (Cartesian radar point cloud)。
笛卡尔雷达点云 (Cartesian radar point cloud)。
2. 校准
从单个传感器的角度出发,校准本质上是指点到世界坐标系 (WCS) 到传感器坐标系的映射。
这种映射是通过分别计算内在和外在变换矩阵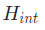 和
和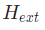 来实现的。传感器的内在参数取决于传感器的内部参数,例如相机的焦距、光学中心和偏斜系数。
来实现的。传感器的内在参数取决于传感器的内部参数,例如相机的焦距、光学中心和偏斜系数。
外部参数取决于传感器相对于世界坐标系的物理位置(3-D translation)和方向(3-D rotation)。在多传感器系统中,校准是指将单个传感器的坐标映射到统一的参考系。
研究人员的目标是转换  从毫米波雷达到相机的
从毫米波雷达到相机的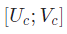 传感器坐标,将它作为统一参考系,主要用于图像数据的视觉检查、推断和注释相,方法相对简单。
传感器坐标,将它作为统一参考系,主要用于图像数据的视觉检查、推断和注释相,方法相对简单。
3. 聚类与关联
每帧中的雷达点云库数据由物体的雷达回波集合和噪声组成,识别和分组与特定物体对应的雷达点需要额外的处理。
研究人员使用匈牙利算法完成将雷达数据分离到与每帧中不同对象相关的集群之外等任务。
包括模拟退火和粒子群算法在内的几种启发式方法,实际操作中会面临计算复杂和随机搜索种子不能保证收敛的挑战。
而匈牙利算法是一种解析多项式时间组合优化算法,可以确保收敛到最优分配解决方案。
基于传感器融合的目标识别方案一般有四个阶段:数据采集和预处理、传感器之间的协同校准和关联、高/ 低级传感器融合特征表示(SFFR)和分类网络。
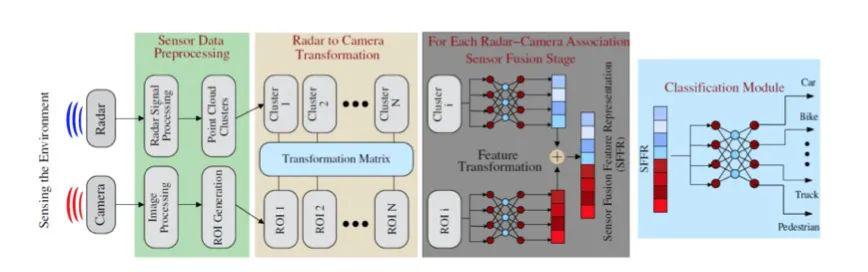 图注:自动多传感器数据集生成的典型用例和动机,协助基于传感器融合的分类。
图注:自动多传感器数据集生成的典型用例和动机,协助基于传感器融合的分类。
如上图所示,雷达和相机数据使用共同校准的变换矩阵关联。然后对每个对应雷达图像对进行特征转换和融合,从而产生SFFR,再将它用于识别检测到的对象的类别。但在单个传感器故障情况下,不相关的雷达和摄像头数据可能会受到传感器特定后备网络的影响。
对此,Arindam Sengupta等人提出的标记雷达图像对的自动生成方法(用于基于传感器融合的分类),和仅使用雷达数据标记的数据集(用于识别目标)。
1. 雷达和相机协同校准
实验中相机的内在参数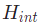 是通过张正友的标定算法获得的。研究人员将雷达1 和雷达2 数据投影到同一张相机图像上,从而检查协同校准精度,定义为雷达检测的目标感兴趣区域,再与总检测量相比。
是通过张正友的标定算法获得的。研究人员将雷达1 和雷达2 数据投影到同一张相机图像上,从而检查协同校准精度,定义为雷达检测的目标感兴趣区域,再与总检测量相比。
所有帧的协同校准精度的平均值为85%,中值为92%,众数则为100%。
 图注:实验的数据采集设置
图注:实验的数据采集设置
2. ROS 管道(ROS Pipeline)
ROS(Robot Operating System)是面向机器人的开源的元操作系统(meta-operating system)。
雷达和摄像头的数据是用ROS 管道获取的,有三个主要包:mmWave_radar、usb_webcam 和 darknet_ros。
mmWave_radar 包将啁啾配置加载到雷达上,缓冲来自雷达的处理数据,并将它发布到 /radar_scan 主题上。
usb_webcam 包从相机(30fps)读取原始图像,并使用估计的相机固有参数来校正和不失真图像,作为压缩消息/image_rect/compressed 发布,并附带时间戳标题。
darknet_ros 包使用 OpenCV 桥收订校正后的图像,然后置于 YOLO 分类网络中,YOLO 网络再通过 /bounding_boxes 消息输出图像中对象的边界框和类别,以及图像采集和预测时间戳。
此外,darknet_ros 包还通过./detection_image 发布图像输出,边界框覆盖在校正后的图像输入上。在数据收集阶段,这四个消息主题都保存在 ROS 包文件中,等待下一步的分析和神经网络训练。
3. 传感器融合数据集生成
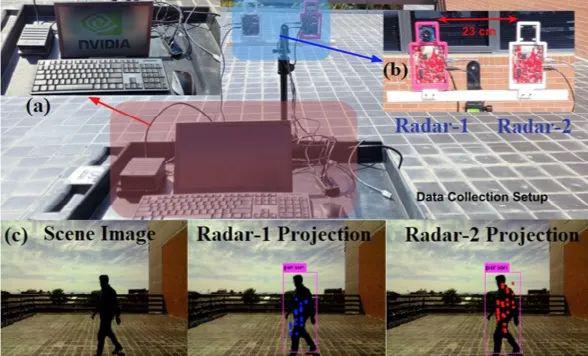
 图注:画面内yolo-雷达协调步骤的图片,研究人员通过该技术标注雷达阵列的信号。
图注:画面内yolo-雷达协调步骤的图片,研究人员通过该技术标注雷达阵列的信号。
第一个数据集由所有 N 帧中给定相同对象的标记雷达图像对组成。
首先使用 PointID 参数聚集雷达点以形成逐帧雷达点云库数据。回想一下,PointID 在帧中始终按升序排列,从 0 开始。
给定帧的雷达时间戳 设置为接收到 PointID=0 的时间戳。
设置为接收到 PointID=0 的时间戳。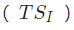 和
和 分别表示图像的时间戳和 YOLO 边界框 (YOLOBBox)预测。
分别表示图像的时间戳和 YOLO 边界框 (YOLOBBox)预测。
在每个雷达帧中,对 3-D 点云库数据执行 DBSCAN 以分离多个目标簇。并对 YOLO 质心和投影雷达簇质心的像素索引进行匈牙利算法进行帧内雷达与图像关联。结果以Numpy 数组的形式保存到磁盘,并以 YOLO 类作为标签。
 图注:传感器融合数据集生成的伪代码。
图注:传感器融合数据集生成的伪代码。
4. 唯雷达数据集生成
第二个数据集仅由雷达数据的标记连续帧组成,作用于仅使用雷达数据识别对象类别的应用程序。
这对 Image-YOLO 管道由于照明不良或遮挡而无法检测到对象而雷达继续检测对象的情况非常有用。在每一帧中,执行具有噪声的基于密度的聚类方法,将点云库集群与不同的目标分离。
 图注:即使 YOLO 偶尔失效,帧间匈牙利算法也可确保对同一对象的雷达连续帧反馈进行标注。
图注:即使 YOLO 偶尔失效,帧间匈牙利算法也可确保对同一对象的雷达连续帧反馈进行标注。
在每一帧 i (i > 1),3-D 簇质心被比较并分配给前一帧 i-1 的 3-D 簇质心,使用匈牙利算法进行帧间簇间关联。每一个检测到的质心,都会被分配唯一的轨道 ID,并在接下来的帧中任何后续关联簇都附加到相同的轨道 ID。
另一个匈牙利算法模块检查投影的集群质心是否可以与给定帧中任何 YOLO 预测相关联。如果 YOLO 分配是可能的,则轨道 ID 会在该帧中使用相关的 YOLO 类信息进行标记。
激光雷达检测的准确性一直是自动驾驶技术的“升级”难点。依据论文数据,该研究的准确率大于97%。也许在它的催化下,快速训练基于深度学习的模型打开了全新可能,加快自动驾驶车辆,甚至是机器人系统的迭代。
目前,作者们已经着手于对自主、医疗、国防和交通领域进行数据驱动的毫米波雷达研究。“我们正在进行的一些研究包括研究基于传感器融合的强大跟踪方案,以及使用经典信号处理和深度学习进一步改善独立毫米波雷达的感知。”
https://techxplore.com/news/2022-02-method-automatically-radar-camera-datasets-deep.html https://www.jianshu.com/p/043966013dde?utm_campaign=hugo&utm_medium=reader_share&utm_content=note&utm_source=weixin-friends
END